树链剖分
树链剖分是一种针对树上问题的很优秀的处理想法。准确的说,它就是一种把“树”映射成“链”的想法。而对于“链”,我们能进行很多处理,诸如挂上线段树,维护前缀和之类。通过这些优秀的数据结构,我们就可以很好的解决有关树上路径的诸多问题……
一 引入
1 模型
对于区间求和、区间最值问题,我们有一个很好的数据结构模型——线段树来解决。
但是如果我们把区间换成在一棵树上呢?
怎样解决?
这时就需要引入“树链剖分”这一概念,即破树为链,再在链上维护线段树。
还有一类问题,是维护树上的边权。不难发现树上除根以外的所有节点 和 它的父节点的边总是唯一的,那么我们可以把边权看作点权,也就是让$v$的点权等于$u\to v$的边权($u$是$v$的父节点),再修改一下细节就好了。
2 概念
学习树链剖分需要先引入几个概念:
- 重儿子($\text{prv}[i]$):节点$i$的子节点中,子树大小最大的那一个。
- 重链:一个节点的重儿子,重儿子的重儿子,……,组成的链。
- $\text{sz}[i]$:以节点$i$为根的子树的大小(节点数量)。
- $\text{prv}[i]$:节点$i$的父节点。
- $\text{dep}[i]$:节点$i$在树上的深度(定义根的深度为$1$)。
- $\text{pos}[i]$:节点$i$映射在线段树上的节点编号,编号按照dfs的先后顺序从小到大编排。
- $\text{tid}[i]$:线段树上的节点$i$映射在原树上的节点编号,与$\text{pos}[i]$互为反函数。
- $\text{top}[i]$:节点$i$所在的重链上,深度最低的那个节点(也可以看作重链的根)。
如下图,标记出了一棵树上的所有重链(注意,每个节点都必定在一条重链上)与重链的根,每个节点的重儿子,节点的深度、子树大小和编号($\text{pos}[i]$)。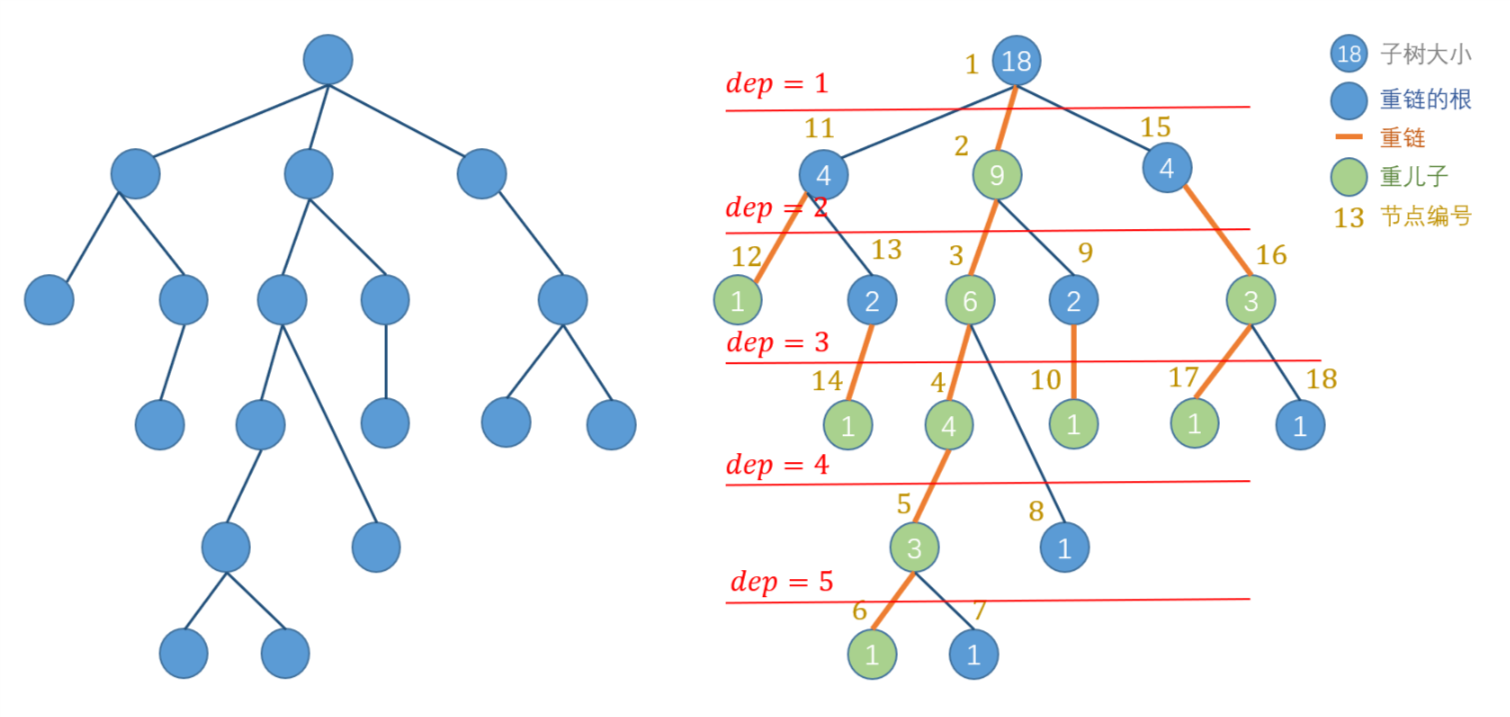
注意:我们对节点进行编号的时候,优先dfs遍历当前节点的重儿子,这样就可以保证一条重链上的编号总是连续的。
二 实现
1 思想
那么怎么实现上面的问题呢?
在处理出节点的dfs编号之后,我们不妨把这$n$个编号当作区间,把每条重链映射在这个区间上,如下图:
显然我们可以用线段树去维护这个区间,然后我们就可以快速的求出一条重链上任意一个点对间所有点的权值和。
跳链操作
不在一条重链上呢?
不妨这样想:我们不断让所在重链的深度(定义为链的根的深度)大的那个点每次跳到它所在重链的根的父节点,也就是另一条重链上。这样,最后总能让这两个点位于一条重链上。
那么我们只需要在节点每条过一条重链时,记录这条重链上所有点的权值和,然后再加上最后在同一重链上是两点间的点权和,就是两点的路径上所有点的权值之和。关于权值和修改的问题也同理。
子树查询
再看修改子树上的所有点权和这个操作。
不难发现以$i$为根的子树,点编号的范围是$[i,i+\text{sz}[i]-1]$。那么只需要在线段树上直接区间修改就好了。
这样,我们就可以在最高$O((log_2)^2n)$的时间里,完成一次 修改/查询 操作。
2 代码
预处理:两遍dfs,分别处理出$\text{prv}[i],\text{sz}[i],\text{prv}[i],\text{dep}[i]$和$\text{pos}[i],\text{tid}[i],\text{top}[i]$。
然后建立线段树,并写好跳链操作就好了。
代码:
模板
1 | const int CN = 2e6+10; |
三 图论应用
树链剖分是一种针对树上问题的很优秀的处理想法。正是因为它太优秀了,所以他并不仅仅能当一个数据结构用,甚至可以被用来解决图论问题。
准确的说,树链剖分就是一种把“树”映射成“链”的想法,就像上面所描述的那样。对于这个“链”,我们就能进行很多处理,诸如挂上线段树,维护前缀和之类。通过这些优秀的数据结构,我们就可以很好的解决有关树上路径的诸多问题。
1 点对LCA
最近公共祖先(Least Common Ancestors,LCA)也是可以用LCA求的。我们对树上的一个点对$(u,v)$进行跳链操作,直到两点处于一条重链上停止,那么此时$u,v$中深度浅(更靠近根)的那个就是$(u,v)$的LCA。
实际上这样就不需要再在树剖上挂线段树了。于是代码长这样:
1 | const int CN = 5e5+5; |
一个LCA的例题:HDU 4547 CD Opt。
2 点对路径和
首先是判联通,这个可以用并查集,不多讲了。
前面提到过树剖在处理边权问题的时候,可以把边权改点权。具体的做法是让边$u\to v$的权变成$v$点的权,因为一个儿子节点只对应一个父节点,也就是只对应一条通向父节点的边。
但是这样实际在统计边权的时候上会多统计一条边,也就是两个点的LCA对应的那条边。于是我们在两个点跳到同一条重链之后(也就是求出了LCA),要把LCA往它的重儿子偏移一个节点,然后再统计边权和。但是有时候还会使得最后这个区间不存在,那么我们加个特判就好了。
另一个边权问题的例子:USACO11DEC Grass Planting。
于是点对间的边权和问题就被转化成了点对间的点权和问题。并且这个点权和还不需要支持修改,于是我们只需要树剖之后,维护一个前缀和就好了。
代码长这样:
1 | const int CN = 1e4+4; |
3 重构树后的树链剖分
两个相邻的点间可能有多条边,那么肯定要保留边权大的。推广,考虑到要保证图的连通性,我们需要选出最少的边,使每条边的权值都尽量大,并且要求这些边不能使图的连通性改变。
那么也就是最大生成树了。重构最大生成树之后,剩下的问题就是一个查询两点路径上的最小边权。这个可以树剖,然后挂一个线段树就好了。
还有一个细节:图不保证联通。这个像上面一样用并查集维护就好了。
代码长这样:
1 | const int CN = 1e5+4; |




